Configuring Gmail Indexing
IPRO can include data sourced directly from an external Gmail location. Indexing and Archiving jobs must be set up to process the data and make the Gmail content available in IPRO Search.
You can only index and archive in Gmail if you previously configured the connection and created the required location in the IPRO Admin UI—see Configuring Gmail Connector.
When the Gmail Archive Storage location or Email (Gmail) Live Location has been created in the IPRO Admin UI and the connection to Gmail has been configured, Indexing and Archiving jobs can be configured for the Gmail source location. Indexing and Archiving is required to make the source data available in an IPRO .
The Indexing job must be set up and run in order to search archive data in Gmail. When the Gmail Index job is configured, messages will be indexed according to the criteria and schedule set.
Indexing must be performed prior to archiving in order to make the archived content searchable—see Configuring Gmail Archiving.
It is not necessary to create a policy to guide this job.
- Select Archiving > Agents > Email Indexing.
- At the bottom-left of the License tab, click Create.
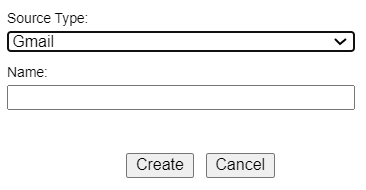
- Select Gmail from the Source Type drop-down menu.

- Give the job a meaningful name and click Create.
- The new job is created and appears under Email Indexing. Click on it.

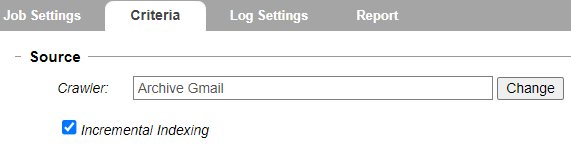
- Open the Criteria tab.

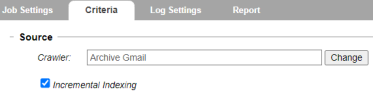
- Navigate to the Source section. In the Crawler field, use Find to identify the Gmail Storage or Live Gmail Location you previously created—see Configuring Gmail Connector.
Click OK. 
- You can enable Incremental Indexing to ensure data is indexed based on the account check point stored on the mail box.
- In the Policy section, you can enable Filter by query. Selecting this option will allow you to enter a policy query in the field below.

- Click Save.
- Open the Job Settings tab.
- Enter a meaningful Description. You can enter the name of the index job.
- Set the appropriate Job Priority. You can choose between Low, Normal, and High. By default, the Priority is Normal.
- Set the appropriate Mode:
- Continuous: Indexes operate on a continual basis without interruption. The index keeps up to date with all changes in the location.
- Pause: Stops indexing. Once the initial index is built, there is no need to continue running it.
- Pause and delete indexes: Stops indexing and deletes the existing index.
- Click Save.
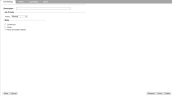
- Logging provides you with detailed job logs that can assist with job troubleshooting, if needed. In the Log Settings tab, configure the desired log settings:
- Disable Detailed Logging (Default): Deactivates logging.
- Enable Logging: Activates logging for troubleshooting purposes.
- Enable Logging Only for the Next Run: Activates logging the next time the job is run, and then automatically returns logging to ‘disabled’ state.

- You can also have email Notifications sent at the completion of the Gmail Index job, along with attachment options.

- For further information on logging—see Configuring Logging.
- Click Save.
- (Optional) In the Report tab, check on the progress of the Gmail Index job.
For further information on reports—see Viewing Reports. - (Optional) Next, to archive Gmail data and search the archived Gmail content—see Configuring Gmail Archiving.






This setting is useful in scenarios where multiple jobs are running concurrently and you want to control which job takes priority with respect to thread allocation. The job priority you select determines which job in the queue is selected next by the Job Manager process, which is responsible for allocating queued job threads to available thread slots on the archive nodes. Prioritization is categorized according to user account. For example, you may want to assign higher priority to crawling files created by VIP users. If a normal priority job is already running and using all available job threads, setting the priority to high and executing it will direct any freed threads to be used on the new high-priority job. This feature works in conjunction with load balancing in order to control crawling job distribution.