Create a Standard Data Extract Job
Data Extract Jobs are based on completed Discovery Jobs. If the Discovery Job was not indexed, searching is not available in the Flex Processor Rules Manager.
The Data Extract Job creates output that contains a paginated text file, an extracted text file, and the original file. It does not output Image Files. The output is stored in the directory that was selected when the Client was created. The following is an example path: \\eCaptureData\ProjectOne\DataExtract Jobs\DE000009\Output\1000\220. The 220 directory contains the output files mentioned at the beginning of this paragraph.
To create a Standard Data Extract Job, perform the following steps:
-
Right-click Data Extract Jobs underneath the proper Custodian.
-
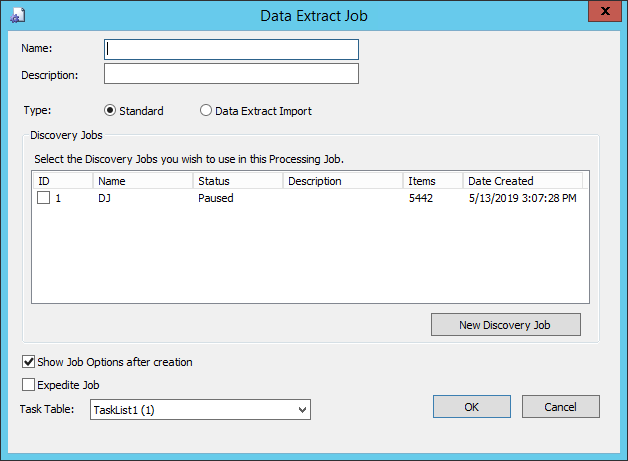
Select New Data Extract Job. The Data Extract Job dialog box appears.
-
Enter a Name.
-
Enter a Description.
-
Choose Standard.
-
Select one or more of the Discovery Jobs you want to use for this Data Extract Job.
-
(Optional) If you want to create a new Discovery Job at this time, click New Discovery Job. After creating the Discovery Job and selecting the Discovery Job options, the newly created Discovery Job will display in the Discovery Jobs list (in the Data Extract Job dialog box) and will be selected. The Discovery Job also displays in the Job Queue grid of the eCapture Controller.
-
(Optional) If you do not want the Data Extraction Job Options to display, clear the Show Job Options after creation check box.
-
(Optional) If you want the job pushed to the front of the queue, select the Expedite Job check box.
-
Select a task table from the drop-down menu. The task table that displays in the field is based on the last task table selected for the Custodian.
-
Click OK. One of the following happens:
-
The Data Extract Job displays in the Job Queue grid of the eCapture Controller.
-
The Data Extract Job Options dialog box appears.
-
-
To set the Data Extract Job options, click the following section to learn more about options for Data Extract Jobs:
 Data Extract Options
Data Extract Options
-
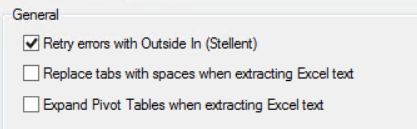
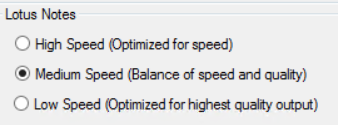
Set the Filtering options for the Data Extract Job. You can create filters either on the Flex Processor Rules Manager dialog on using the Flex Processor Rules Wizard, for more information, see:
- When finished, click OK to exit the dialog box.



Related Topics