A completed may be modified
in order to make modifications for de-duplication and to fix node and/or
item level exceptions.
As of version 2016.3.3, node level exception errors
may be requeued from the ADD for Streaming Jobs
submitted through ADD.
ADD
Copy count validation errors may be requeued directly from the ADD
Manager. Errors may be examined while the Streaming Discovery Job
is processing.
- Under the Management Tab,
select a Client, click Discovery Jobs, and select the Discovery
Job to be modified.
- Click
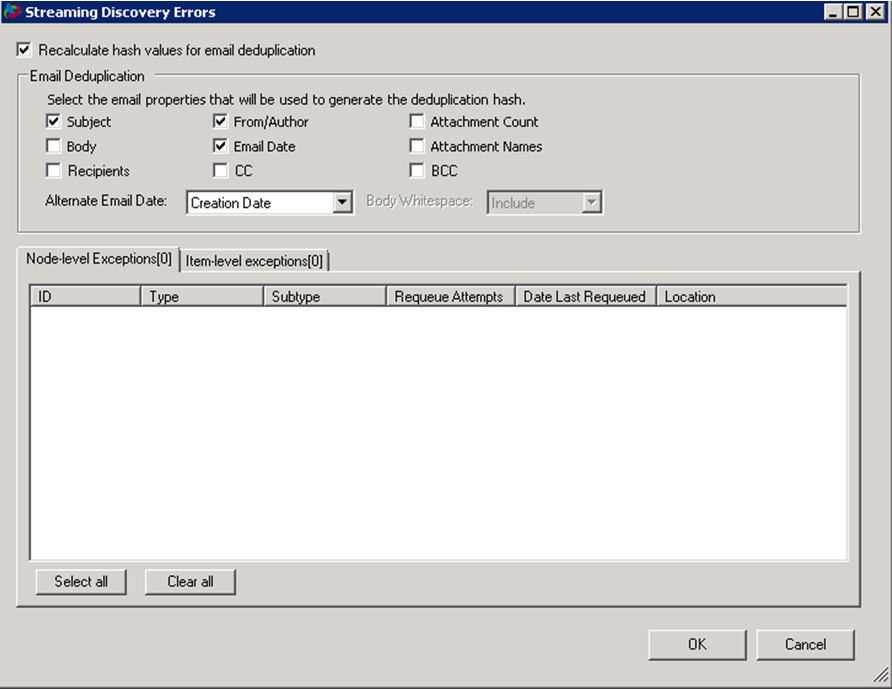
 The Streaming Discovery Errors
dialog appears.
The Streaming Discovery Errors
dialog appears.
 Recalculate
hash values for email de-duplication
Recalculate
hash values for email de-duplication
When selected, recalculates the hash value for e-mail messages. Select the e-mail
properties (under Email ) that will be used to calculate the hash.
E-mail
De-duplication
Method of gathering and creating the MD5Hash has changed for newly created Projects.
Hashing of e-mails uses the UTC time to ensure proper de-duplication across time
zones.
In most cases, MD5 hash values are calculated on the file itself. For more reliable
de-duplication of emails though, it is required that de-duplication occur on the
information contained within it and not the file itself. There are many reasons for
this; the simplest is the fact that when an email is saved out of its container (PST,
NSF, etc.) the file that is created contains information that would change the hash
value of the same email each time that the email was saved out.
When an email is discovered within eCapture, it is assigned a hash value based on fields chosen by the user. The values of these fields are concatenated and the text is hashed. Select from the following email fields to generate the hash value:
- Subject
- From/Author
- Attachment Count
- Body - when this option is selected the default setting is to include the body whitespace.
Whitespace in the e-mail body could cause slight differences between the same e-mails,
which could result in different hashes being generated. If you do not wish to include
the whitespace, select remove from the Body Whitespace drop-down list to remove all
whitespace between lines of text in the email body prior to hashing E-mail Date: The following message types use the specified date values: Outlook:Sent Date, IBM (formerly Lotus) Notes: Posted Date, RFC822: Date, and GroupWise:
Delivered Date. From the Alternate Email Date drop-down list, select either Creation Date or Last Modification Date. The selected value will be used when calculating the MD5 hash in the event that the normal E-mail Date value is not present. This commonly occurs for Draft messages that have not been sent.
- Attachment Names
- Recipients
- CC
- BCC
Start Time is always used if it exists.
By default, Subject, From/Author, Email Date, and an Alternate Email Date of Creation
Date are used for email hash generation.
Exceptions
As of version 2018.5.2, the configured case-level password list is utilized when an encrypted document is requeued, due to a ‘Detect Container’ discovery error. This applies for both item-level exceptions and node-level exceptions. If a password is received after the Streaming Discovery job was initially submitted, an attempt is made to extract from these files without the need to generate a separate job. Note: Container types .NSF and .PST are not directly supported by this change.
The -level exceptions (n) tab lists the number of node-level exceptions in parenthesis.
Click the tab to view the exceptions. A node level error means that a problem was
encountered extracting the contents of a container (e.g. Email store - folder within
the email store, or a loose file with attachments). Node level errors indicate items
are missing from the production set.
The Requeue Attempts column lists the number of times the node-level exception was
requeued. The Date Last Requeued column lists the date the last time the node-level
exception was requeued.
To view the error details for the ADD Streaming Discovery Job:
- Locate
and click the Ipro ADD Streaming Discovery Job in the Client Management tree view.
- Click the Node-level exceptions (n) tab located in the Client Management tab Status
and Summary Panel.
- Double click the error to open the Discovery Error Information
dialog. If more than one error is listed, click Next to advance to the next error’s
details.
- When through reading the error details, click OK to close the dialog.
-
The Item-level exceptions (n) tab lists the number of item-level exceptions in parenthesis.
Item Level errors mean that an error was encountered on a specific item. If items
in the production are password protected these should be reflected in the Detailed
Error Report that lists errors and status messages encountered during Streaming Discovery.
The Count, Type, and Exception Type are shown for each item-level exception.
|

|
Note: This information is also available under the Item-level exceptions (n) tab
for the Streaming Discovery Job located in the Client Management tab Status and Summary
Panel.
|