Architecture Overview
ARCHIVE consists of a number of servers and processes.
Archive Collection servers run on Windows 2016 virtual machines (VMs) and are responsible for reading data and file documents from the source systems (on-premise email servers, local Windows File Systems (WFS) and cloud-based services). They operate in a cluster allowing full redundancy with the number of servers defined by the amount of data and number of users. Typically, a single archive server can process approximately 2,000 users daily.
Index servers run on a Linux virtual machine and are responsible for indexing all content from emails, email attachments, and documents.
In its most basic configuration, ARCHIVE can function with a Master Archive node and a single Index server. However, ARCHIVE is typically run in a cluster. The size of the cluster you require depends on a variety of factors:
- Number of users
- Volume of archived data to be searched
- Volume of live mail to be audited
- Frequency that data is accessed
- Frequency and scope of eDiscovery requests
- Configuration of the mail environment
- Requirements to crawl file servers
The following diagram represents a typical cluster consisting of a master archive server and two worker nodes, as well as two index servers.
This guide assumes a first-time deployment of ARCHIVE, starting with a single archive node and two index nodes, with the possibility of further nodes being added at later stages.
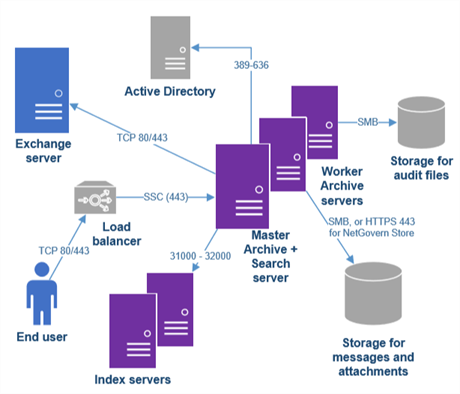
ARCHIVE is a modular framework. Input and output from the engine is handled through the storage layer and the connector layers. These layers provide modular components which connect to different mail systems and databases, as well as different storage devices.