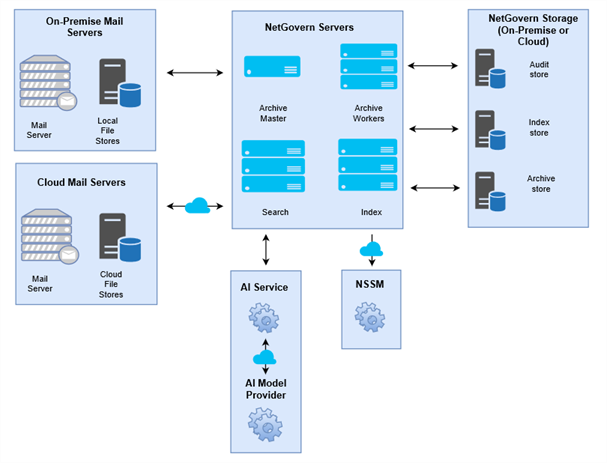
Architecture Overview
ARCHIVE is deployed as a multi-node cluster. Each node runs a sub-set of services that can be deployed differently, depending on the load on each machine. In its most basic configuration, ARCHIVE can function with a single Archive node acting as Master that hosts the Search service, as well as a single Index server node. Worker nodes are optional. Master, Worker and Search nodes are deployed on Windows 2016 virtual machines. Index Server nodes are Linux virtual machines based on Centos 7.5 OS.
ARCHIVE typically runs more than two nodes. The size of the cluster depends on a variety of factors:
- Number of users
- Volume of archived data to be searched
- Volume of live email to be audited
- Frequency that the data is accessed
- Frequency and scope of eDiscovery requests
- Configuration of the mail environment
- File indexing and cloud server requirements
ARCHIVE connects to different cloud and on-premise data sources to collect data. The results of these collections can be:
- Archived in attached data stores
- Indexed to allow for search and eDiscovery on the content using IPRO Search.
- Both archived and indexed
The current out-of-the-box data sources supported are:
On-Premise
- Exchange
- Windows File System
- SharePoint
- GroupWise
- Outlook PSTs
Cloud
- Exchange O365
- SharePoint
- OneDrive
- Box for Business
- ShareFile
- Egnyte
ARCHIVE accesses data using a connector approach that allows for easy access to additional data sources.
The following diagram represents a typical cluster consisting of a Master Archive server and two Worker nodes, as well as two Index servers.